
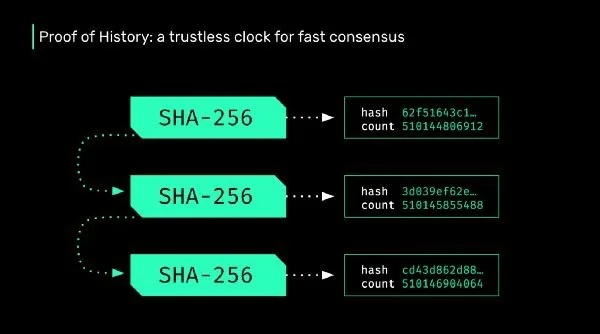
Solana is a high performance blockchain that uses a concept called Proof of History to achieve a cryptographically secure and trustless time source.
In July, we pushed out our multinode testnet and since then, we’ve been working tirelessly to prove our theory about building a scalable blockchain that could allow for 710k TPS.
When Solana reaches full speed and capacity (710,000 transactions per second on a 1 gigabit network) it will be generating almost 4 petabytes of data a year. If every node in the network is required to store all that data, it would limit network membership to the centralized few that have that kind of storage capacity. Luckily, our Proof of History technology can be leveraged to avoid this situation, allowing a fast-to-verify implementation of Proof of Replication and enabling a bit torrent-esque distribution of the ledger across all nodes in the network.
The basic idea of Proof of Replication is to encrypt a dataset with a public symmetric key using CBC encryption and then hash the encrypted dataset. Unfortunately, the problem with this simple approach is that it is vulnerable to attack. For instance, a dishonest storage node can stream the encryption and delete the data as it’s hashed. The simple solution is to force the hash to be done on the reverse of the encryption, or perhaps with a random order. This ensures that all the data is present during the generation of the proof and it also requires the validator to have the entirety of the encrypted data present for verification of every proof of every identity. So the space required to validate is (Number of CBC keys)*(data size).
Our improvement on this approach is to randomly sample the encrypted blocks faster than it takes to encrypt, and record the hash of those samples into the PoH ledger. Thus the blocks stay in the exact same order for every PoRep and verification can stream the data and verify all the proofs in a single batch. This way we can verify multiple proofs concurrently, each one on its own CUDA core. With the current generation of graphics cards our network can support up to 14k replication identities or symmetric keys. The total space required for verification is (2 CBC blocks) * (Number of CBC keys), with core count of equal to (Number of CBC keys). A CBC block is expected to be 1MB in size.
We now have to construct a game between validators and replicators that ensures that replicators are generating proofs, and validators are actually verifying proofs.
Validators for PoRep are the same validators that are verifying transactions. They have some stake that they have put up as collateral that ensures that their work is honest. If you can prove that a validator verified a fake PoRep, then the validators stake can be slashed.
Replicators are specialized thin clients. They download a part of the ledger and store it and provide PoReps of storing the ledger. For each verified PoRep, replicators earn a reward of sol from the mining pool.
We have the following constraints:
- At most 14k replication identities can be used, because that’s how many CUDA cores we can fit in a $5k box at the moment.
- Verification requires generating the CBC blocks. That requires space of 2 blocks per identity, and 1 CUDA core per identity for the same dataset. So as many identities at once should be batched with as many proofs for those identities verified concurrently for the same dataset.
How we are thinking about doing this is as follows:
- Network sets the replication target number — let’s say 1k. 1k PoRep identities are created from signatures of a PoH hash. So they are tied to a specific PoH hash. It doesn’t matter who creates them, or simply the last 1k validation signatures we saw for the ledger at that count. This maybe just the initial batch of identities, because we want to stagger identity rotation.
- Any client can use any of these identities to create PoRep proofs. Replicator identities are the CBC encryption keys.
- Periodically, at a specific PoH count, replicators that want to create PoRep proofs sign the PoH hash at that count. That signature is the seed used to pick the block and identity to replicate. A block is 1TB of ledger.
- Periodically, at a specific PoH count, replicators submits PoRep proofs for their selected block. A signature of the PoH hash at that count is the seed used to sample the 1TB encrypted block, and hash it. This is done faster than it takes to encrypt the 1TB block with the original identity.
- Replicators must submit some number of fake proofs, which they can prove to be fake by providing the seed for the fake hash result.
- Periodically at a specific PoH count, validators sign the hash and use the signature to select the 1TB block that they need to validate. They batch all the identities and proofs and submit approval for all the verified ones.
- Replicator client submit the proofs of fake proofs.
For any random seed, we force everyone to use a signature that is derived from a PoH hash. Everyone must use the same count, so the same PoH hash is signed by every participant. The signatures are then each cryptographically tied to the keypair, which prevents a leader from grinding on the resulting value for more than 1 identity.

Image from John Klossner @ Computer World
We need to stagger the rotation of the identity keys. Once this gets going, the next identity could be generated by hashing itself with a PoH hash, or via some other process based on the validation signatures.
Since there are many more client identities then encryption identities, we need to split the reward for multiple clients, and prevent sybil attacks from generating many clients to acquire the same block of data. To remain BFT we want to avoid a single human entity from storing all the replications of a single chunk of the ledger.
Our solution to this is to force the clients to continue using the same identity. If the first round is used to acquire the same block for many client identities, the second round for the same client identities will force a redistribution of the signatures, and therefore PoRep identities and blocks. Thus to get a reward for storage clients need to store the the first block for free and the network can reward long lived client identities more than new ones.
Grinding Attack Vectors
- Generating many identities to select a specific block. The first time an a keypair is used to generate an identity it’s not eligible for reward and it’s not counted towards the replication target. Since identities have no choice on what PoH to sign, and all have to sign the same PoH for block assignment, the second generation of blocks is would be unpredictable from the first set.
- Generating a specific PoH hash for a predictable seed. This attack would only influence one seed, so 1 block from many. With the total number of possible blocks of CBC keys * data slices, it is a reward loss the network can afford.
Some key takeaways
- We can reduce the cost of verification of PoRep by using PoH, and actually make it feasible to verify a large number of proofs for a global dataset.
- We can eliminate grinding by forcing everyone to sign the same PoH hash and use the signatures as the seed.
- The game between validators and replicators is over random blocks and random encryption identities and random data samples. The goal of randomization is to prevent colluding groups from having overlap on data or validation.
- Replicator clients fish for lazy validators by submitting fake proofs that they can prove are fake.
- Replication identities are just symmetric encryption keys, the number of them on the network is our storage replication target. Many more client identities can exist than replicator identities, so unlimited number of clients can provide proofs of the same replicator identity.
- To defend against grinding client identities that try to store the same block we force the clients to store for multiple rounds before receiving a reward.
— —
Want to learn more about Solana?
Check us out on Github and find ways to connect on our community page.