
This is a live document highlighting weekly updates from TdS. Make sure to check back each week for additional details.

Week 3
This has been a major week for us as we’re getting ready to say goodbye to the v0.23.X release line and upgrade to v1.0.X, which is a significant milestone as this release line is intended for soon after our Mainet Beta Launch. With this major milestone we want to give a heartfelt thank you to everyone that has been involved thus far but also all the Dry Runs leading up to this as well that made this all possible.
Compensation
As a small gesture of recognition, all validators that actively participated in Stage 1 will be compensated with additional tokens on top of the base amount, which will be calculated determined by the # of bugs successfully identified during Stage 1. This will be calculated by:
Critical Bugs
Total # critical bugs identified x Compensation amount for bug / total validators = additional compensation per Validator
Non-Critical Bugs
( total non-critical bugs identified x compensation amount for bug ) / total validators = additional compensation per Validator
Notes:
- Delinquent and non-responsive Validators that did not meet participation requirements will not be included in the calculation or be compensated
- For Successful attacks executed by a specific party/parties, additional compensation will be provided to the respective parties directly, and are not part of the calculation
Breaking: Is Keanu Reeves the real One? Both Chorus One and Certus One claim otherwise in their latest attack
Chorus One and Certus One were back at it again. Combining efforts to successfully execute two separate attacks simultaneously during a cluster restart as we upgraded to the SLP2 network while integrating the latest release v0.23.6 release from TdS.
Chorus One’s Attack
As nodes start, they attempt to fetch the genesis config and a snapshot from the node with the highest advertised slot. This helps them find a snapshot that’s as close to the head of the chain as possible, minimizing the catch-up time. But how the nodes advertise their highest slot isn’t trusted, and nodes can lie. Chorus One made their node lie, which caused all the validators to come online to try to fetch the genesis config from them. But the genesis config that the Chorus One node returned was bogus, which caused the nodes to abort. Effectively a DoS attack preventing any node from starting up.
This DoS attack is particularly effective when booting up a new cluster. However, it’s still impactful even when attempted on a live network, by slowly killing the cluster as nodes attempt to restart.
The solution is for this will be to blacklist nodes that return a bad genesis config and/or snapshot, and then retry from another node. Which we’ll be working on implementing in the coming week.
Certus One’s Attack
At the same time, Certus One was running several nodes that served up an infinite file for a snapshot, which prevents validators from starting since they never stop downloading. This wasn’t a complete DoS as there were other nodes with valid snapshots, however if Validators got unlucky, then they’d have to continuously restart their node until they avoid the infinite file.
Issues Identified During TdS: Stage 1 So Far
During the course of Stage 1 we successfully identified a total of 13 new issues within the v0.23.X release:
Total # of Non-Critical Bugs: 11
- Bootstrap leader sending bad snapshots — Closed
- Gossip not filtering out duplicate IP’s — Closed
- Validator uptime calculation incorrect — Closed
- Validators picking up outdated snapshots from delinquent Validators — Closed
- Issue with the ‘solana catch-up’ command
- Unreasonable writes to disk with RocksDB
- Validators falling behind in slots in v0.23.6
- tds.solana.com OOMs shortly after restarting
- Snapshots are taking too long to unpack and process
- Resistance to multi-hour network outage
- Loss of consensus in TdS
# of Critical — 2
- DoS attack by Certus One — Fixed
- Bogus genesis.tar.bz2 files can DoS cluster boot by Chorus One — Closed
- Zero-stuffing genesis/snapshot compressed archives to fill up the disk by Certus One
We spent most of that week working through these issues above, and kept the TdS cluster offline for several days until we had a fix for the some of the critical attacks highlighted identified thanks to our Validator community including several high-priority stability issues related to snapshots.
These fixes were captured in release v0.23.6 and used to bring the Tour de SOL cluster back online during the weekend for a final stress test which went well! Obviously there are still several known issues yet to be rectified (as highlighted above) in this version, but overall we’ve come a long way from when we first started Stage 1.
So what’s next?!
With the new release stress-tested, we’ve used it to upgrade the SLP1 cluster to SLP2 so that partners integrating into Solana can also reap the benefits of these latest improvements as well.
As for the TdS network, we intend to transition soon into testing out our Mainnet Beta release v1.0.X, however, we will retain the same ledger after the upgrade (meaning everyone who is currently delegated remains so). The v1.0.x release line (previously known as v0.24.0) is an extremely important release for us, as it’ll be critical for the launch of Solana’s Mainnet Beta upon post-stress-testing. So over the next few weeks, we look forward to coming back together with our existing Validator community and welcoming new participants!
Note: We also plan on putting together a delegation bot after implementing the v1.0.X release that will automatically add a delegation to new Validators that are current, and remove delegation from delinquent Validators.
Week 2
Welcome back to everyone who’s been following along on our progress during Tour de SOL. It’s been another event-filled week. We’ve shipped several fixes to issues identified over the past few days, while some issues remain outstanding as we expect them to take longer to fix.
PROGRESS ON CRITICAL BUGS
Certus Ones’ DoS Attack
For the first several days last week, we kept the network offline as we attempted to quickly fix the bug highlighted by Certus One’s successful DoS attack, however after working on it for several days we concluded that the fix would require some additional time and effort to be resolved. Therefore we decided to bring the network back up first:
- As we had several other fixes for other issues ready to be implemented
- Allow us to continue identifying more bugs
- With an agreement together with the Validator community that the DoS attack would be off-limits until advised otherwise
Other High-Priority Stability Issues
Outside of the attack mentioned above, we still have several other issues which we’ll be focusing on for the coming weeks:
- Snapshots loading very slowly: Snapshots are taking over 1000 slots to unpack and process across both TdS and SLP due to the large number of account files in them. Thereby slowing down Validators from being able to quickly boot and restart
- Validators can accidentally fetch snapshots from delinquent Validators: When a validator comes up and looks for a snapshot over RPC, it can easily pick a delinquent validator and thus get a very old snapshot.
- Intermittent Consensus Issue 1
NETWORK UPGRADES
Tofino v0.23.4
The cluster was restarted on the 12th of February with version v0.23.4, capturing fixes in the following areas:
- Snapshots
- Repair
- Gossip Network
We successfully upgraded the cluster with the new version the following day, and our bootstrap Validator node finally managed to distribute its stake to the rest of the cluster such that it represented less than 33% of the active stake.
Tofino v0.23.5
We followed up with another version on the 14th of February with another update to rectify a long-standing out-of-memory issue that was affecting some Validators
Final Comments
As of today, the network is still down due to the issue mentioned above where Validators accidentally fetch snapshots from delinquent nodes. Until this is resolved we won’t be restarting the network just yet as it’ll likely cause the network to crash again after a few days.
Week 1
We’re officially a week into Stage 1 of Tour de SOL (TdS), and what a week it has been. Our goal was to begin to stress test our latest release v0.23.3, and iron out any major issues in this release with the aim to use it to upgrade our Soft Launch Phase 1 (SLP1) cluster to the Global Cluster (GC), the first major release of our cluster. As of now, we’ve had 2 cluster restarts, 1 critical bug identified, and a series of smaller bugs identified which we’re currently working through. Suffice to say it’s been everything we hoped it would be when we first set out to launch this event.
ATTACKS/BUGS
Congratulations to the team at Certus One, who successfully submitted the first PR for a critical bug! With this attack, they managed to weaponize a memory leak bug in the gossip network to starve the kernel allocator, which would take down any Validator on the cluster (either one at a time, or all at once).
If you refer to the diagram below, this is how the cluster reacts when this attack is performed. The diagram on the left shows an ever-growing gap between the latest block and the last time a block was finalized when a healthy cluster would instead show a flat line. The diagram on the right should look like a linearly increasing function, instead, it’s a flat line indicating that consensus isn’t being achieved.
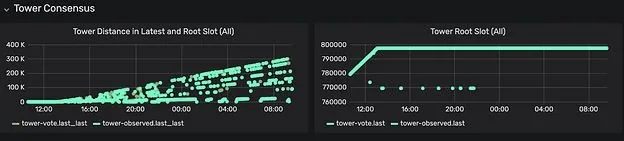
Diagram 1: Aftermath of Attack
OTHER ISSUES IDENTIFIED
The great news is that despite the following 2 issues, the cluster managed to stay alive, however, it did lead to a reasonable amount of on-boarding friction for Validators:
- Mixed Public Keys across Solana Clusters
- The gossip networks across both TdS and SLP1.1 merged into a larger cluster during the on-boarding period.
- A few weeks ago, some of you may have seen our announcement about the launch of our SLP1 cluster 1, which runs in parallel to TdS. To connect to this, and any of our other clusters, the process is that we typically require Validators to provide us with their public key, a public identifier for their node.
- Therefore as Validators started to connect to the newly setup TdS cluster during the initial 24-hour onboarding period, we collected their public keys in advance so that we could delegate tokens to them, and get them staked.
- Some of the Validators coming online, re-used the same public keys that they were using for the SLP1 cluster. As a result, these Validators — which couldn’t identify that the SLP1 cluster and the TdS clusters were separate — merged the gossip clusters between the two into a larger whole, and eventually turned Validators delinquent.
- Overloaded RPC Entrypoint
- The RPC entrypoint for the tds.solana.com Validator was added to gossip multiple times, leading to excessive inbound traffic, inefficient management of the additional traffic eventually lead to our the Validator to run out of memory.
- For Validators joining the Tour de SOL cluster, there are two methods of connecting their Validator:
- Using the existing RPC entrypoint provided by Solana
- Setting up their own RPC entrypoint
- The first option is by far the most convenient. However, during the first 48 hours of the cluster coming online, Validators were finding that they were having intermittent success in utilizing the single RPC entrypoint that we had prepared after multiple attempts.
- While we’re still debugging this, we observed two key issues. First was that our RPC entrypoint was being added to the gossip network multiple times (at least 10 times) leading to a significant amount of increased traffic, which was due to a snapshot issue. The second issue which became apparent as a consequence of that was that, the RPC node wasn’t able to properly manage the extra traffic and as a result ran out of memory. It’s possible there are other factors involved, however we’re still investigating as of this time.
CLUSTER RESTARTS
- Failed Migration of Bootstrap Leader Node
- In an attempt to migrate the bootstrap node from Google Cloud into a Co-Location setup, causing it to re-transmit a block and the rest of the cluster forked away, therefore permanently losing consensus.
- Cluster Outage in Data Centre
- Due to a cluster outage in our Data Centre which was hosting our bootstrap node, the cluster stopped making progress, requiring us to restart the cluster.